Article court.
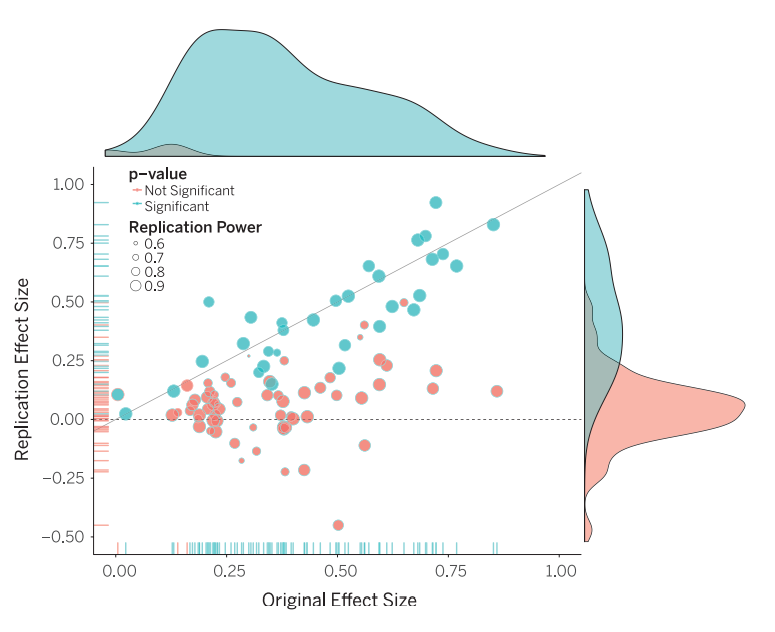
Récemment, j’ai pris connaissance d’une étude datant de 2015 remettant en cause un certain nombre de connaissances que je pensais être suffisamment sûres et vérifiées pour être utilisées au quotidien. Cette étude portant sur la reproductibilité d’une centaine d’études scientifiques dans le domaine de la psychologie nous apprend que seulement 36 % des études testées avaient des résultats significatifs par rapport à 97 % des recherches initiales. En statistiques, le résultat d’études qui portent sur des échantillons de population est dit statistiquement significatif lorsqu’il semble exprimer de façon fiable un fait auquel on s’intéresse, par exemple la différence entre 2 groupes ou une corrélation entre 2 données.